
Swift2.0中字符串的设计
Swift中提供了一个高性能的,兼容Unicode的字符串实现作为其标准库中的一部分.在Swift2中,String类型不再实现CollectionType协议.在以前String字符串是一个由Character字符组成的集合,其表现类似于一个数组.而现在,String则是提供了一个characters属性用来暴露字符集合.
为什么会有这样的变化呢?尽管把字符串当做一个字符的集合看起来更自然.但是其实String字符串类型的操作与Array,Set或者Dictionary等集合一直都是完全不同的.但自从Swift2增加了协议扩展后,针对这些差异有必要进行一些根本性的变化了.
Different Than the Sum of Its Parts
每一个部分和的不同计算
当你给一个集合增加一个元素的时候,你期望的是这个集合将包含这个元素.换句话说,当你给一个数组增加一个值后,这个数组将会包含这个值.这同样适用于Set和Dictionary.但是,当你给字符串增加一个组合标记字符(combining mark character)的时候,这个字符串内容本身会发生变化.
比如以字符串cafe为例,它由c,a,f,e四个字符组成:
|
|
这个时候如果你给字符串增加一个组合重音字符U+0301也就是´.这个字符串仍然只有四个字符,但是最后一个字符现在变成了é:
|
|
这个时候,这个字符串的characters属性中并没有包含原来的小写字符e,并且也没有包含新加的组合重音字符´.相反的,现在字符串包含了加上了重音符的小写字符é:
|
|
如果其他的集合操作也像字符串那样.那么,它们的结果就会有令人出乎意料的表现.比如把UIColor.redColor()和UIColor.greenColor()放入到一个Set集合中,那么这个时候集合中就应该会包含一个UIColor.yellowColor()
Judged by the Contents of Its Characters
判断字符内容的相等
另外一个字符串与集合不同的地方在于他们判断相等的方式.
- 两个数组只有当他们有相同数量的元素,并且每一个相同下标的元素都相同,那么这两个数组才相等.
- 两个Set只有当他们有相同数量的元素,并且在一个Set中的所有元素都在第二个Set中都存在,那么这两个Set才相等.
- 两个Dictonary只有当他们有相同的
Key和ValueSet,那么这两个字典才相等.
但是,String字符串的相等是基于一种规则相等(canonically equivalent)的方式.当字符拥有相同的语义和表现的时候,我们就认为字符是规则相等的.这个时候,两个字符背后的Unicode有可能是不一样的.
比如朝鲜的文字系统,它是由24个字母,Jamo,元音以及辅音组成的.当我们写字的时候会把这些元素进行组合.比如,字가([ga])是由两个字符ᄀ([g])和ᅡ([a])组成.这在Swift中,无论两个字符串是由分解的字符或者是由预组合的字符序列组成的.只要他们的语义和表现是相同的,那么就认为它们是相同的:
|
|
这再次说明,字符串的这种行为与Swift中其他的集合类型是完全不同的.否则如果一个数组中有🐟和🍚两个值,那么他们就是被认为是与🍣相等的.
Depends on Your Point of View
选择何种表现取决于你的使用
字符串并不是一个集合,但是它确实又提供了一些与CollectionType协议相同的表现
characters是一个Character字符值或扩展字元簇(extended grapheme clusters)的集合.unicodeScalars是一个Unicode纯量(Unicode scalar values)的集合uft8是一个UTF-8字符集编码的集合uft16是一个UTF-16字符集编码的集合
如果我们把前面café这个例子中的[c,a,f,e]和[´]这几个字符,用字符串中的这几个属性来表示.那么他们就应该是如下表所示: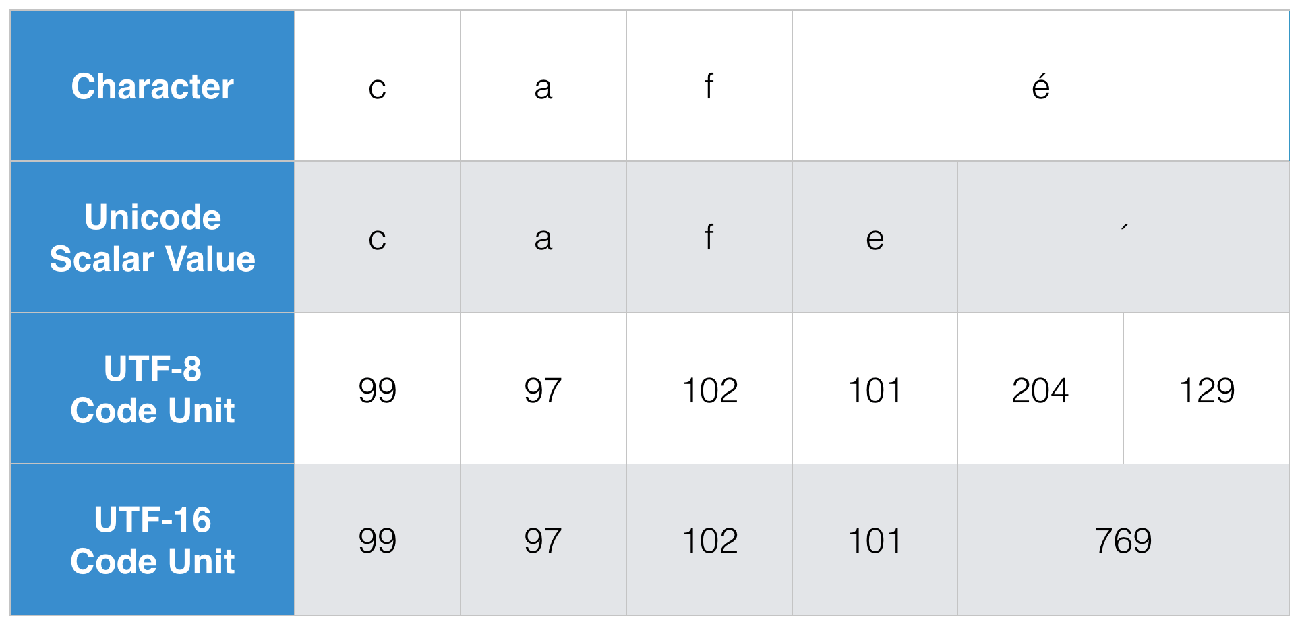
characters属性表示的是扩展字元簇.它与用户所直观看到的字符是相近的(由c,a,f,é四个字符组成).这是因为一个字符串必须能迭代整个串中的每一个位置(每一个位置都被成为一个代码点(code point)),以便能在O(n)时间复杂度上执行存取该属性的操作,并获取字符串的边界.当处理一个包含了人类可读的文字或者高度地域敏感的Unicode编码算法,比如用作localizedStandardCompare(_:)方法的入参或者localizedLowercaseString属性的值的时候,应该使用这种逐个字符的处理方式.unicodeScalars属性暴露了字符串中基本Unicode纯量的存储.当一个原始的字符串是由预组合字符( precomposed character)é组成,而不是由分解成的两个字符e+´组成,那么你应该更倾向于使用这个API来进行更底层的字符串数据的操作.utf8和utf16属性分别被用来提供UTF-8与UTF-16的代码点的操作.这些值通常被用于在写入真正的文件系统的时候转换成某些特定的编码.UTF-8编码通常被用作许多POSIX字符串API的处理.而UTF-16则是更多的用于Cocoa&Cocoa Touch框架,以计算字符串的长度与偏移量.
有关如何在Swift中使用字符串以及字符的更多信息,可以阅读The Swift Programming Language和Swift Standard Library Reference.
原文链接:Strings in Swift 2
翻译:翔妖除魔

